Cleaning Data with OpenRefine
About the Data
In this demo we are going to attempt to clean a public data set of museum metadata published by the Powerhouse Museum in Sydney, Australia. Previously, this sample dataset was available directly from the Powerhouse Museum site, but they have since made the collection accessible via API. The sample data reflects a snapshot of the data at a specific time. Since we are trying to demonstrate a lot of features, some of the steps will be very “destructive” to the data (but our original data is still safe).
Download phm-collection.tsv
The data fields are
- Record
- ID
- Object Title
- Registration Number
- Description.
- Marks
- Production Date
- Provenance (Production)
- Provenance (History)
- Categories
- Persistent Link
- Height
- Width
- Depth
- Diameter
- Weight
- License info
Creating a project
Projects can be created from data on your computer, data on the web, pasting into the clipboard, connecting to a database, or linking to Google Sheets. As a reminder. OpenRefine never changes your original data, and information is not sent over the Internet!
OpenRefine can accept a variety of data types, including CSV/TSV/*SV, line-based text files, fixed-width field text files, JSON files, RDF files, XML files, and Excel files. I have found that simple *SV files tend to work the best.
OpenRefine data preview page will attempt to identify the file-type, and the available options will vary based on that file-type. For our museum data, OpenRefine correctly identified it as TSV.
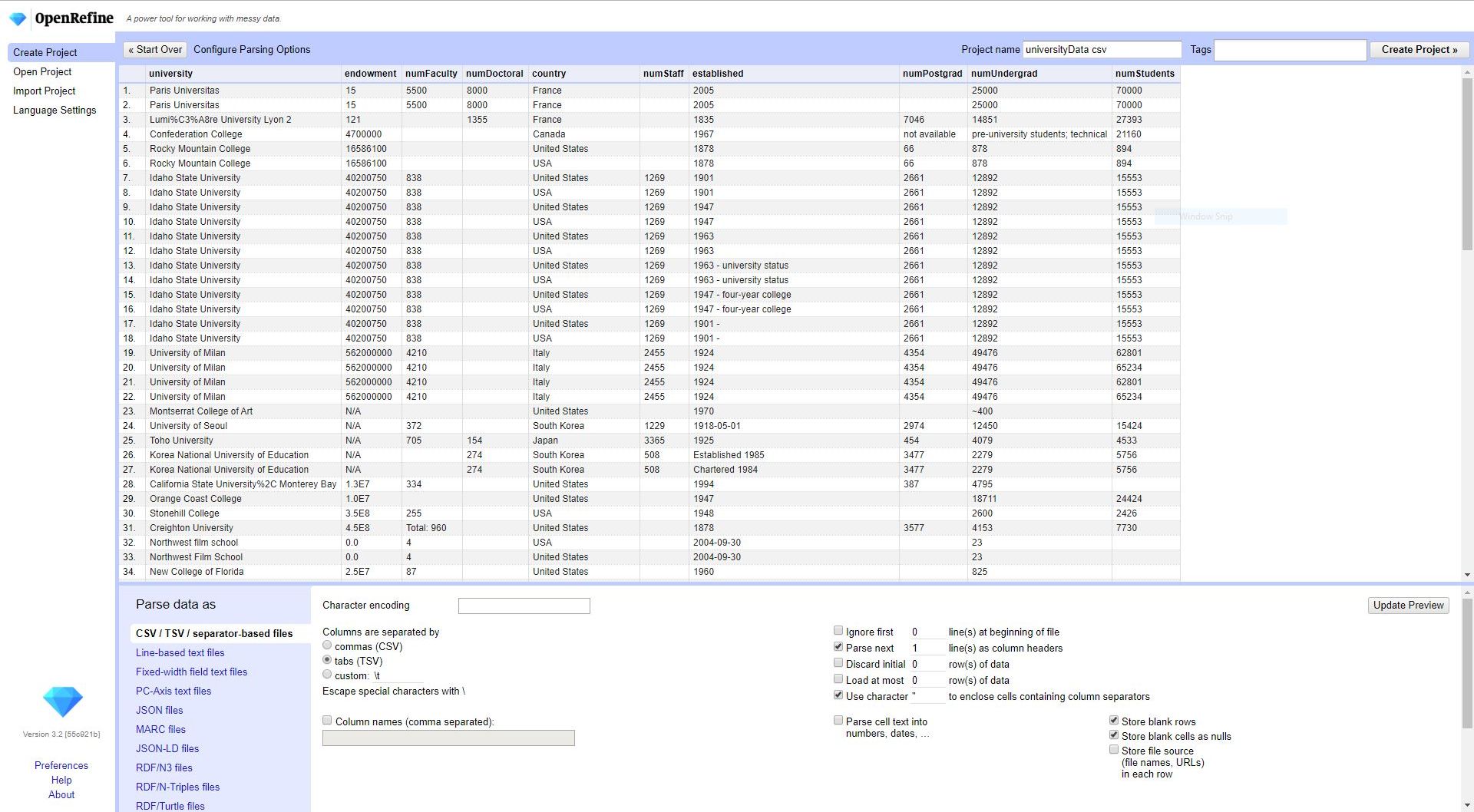
Navigating OpenRefine
- Data manipulation happens through pull-down menus associated with each column.
- OpenRefine only displays a few fields at a time - it is acting as a preview of the data, but the actions taken are on all cells in a column.
- You can adjust the number of visible fields and navigate forward/backward through the pages of data.
Text Filters
- Text filters can be used to isolate specific rows that contain the text. They can be used to quickly isolate rows for further manipulation.
- The dialog box allows for case-sensitive filters and regular expressions.
- Regular expressions can be very powerful for querying data, but a bit outside the scope of this workshop. I regularly use a regular expression to find rows that do not have the word: ^((?!Pennsylvania).)*$
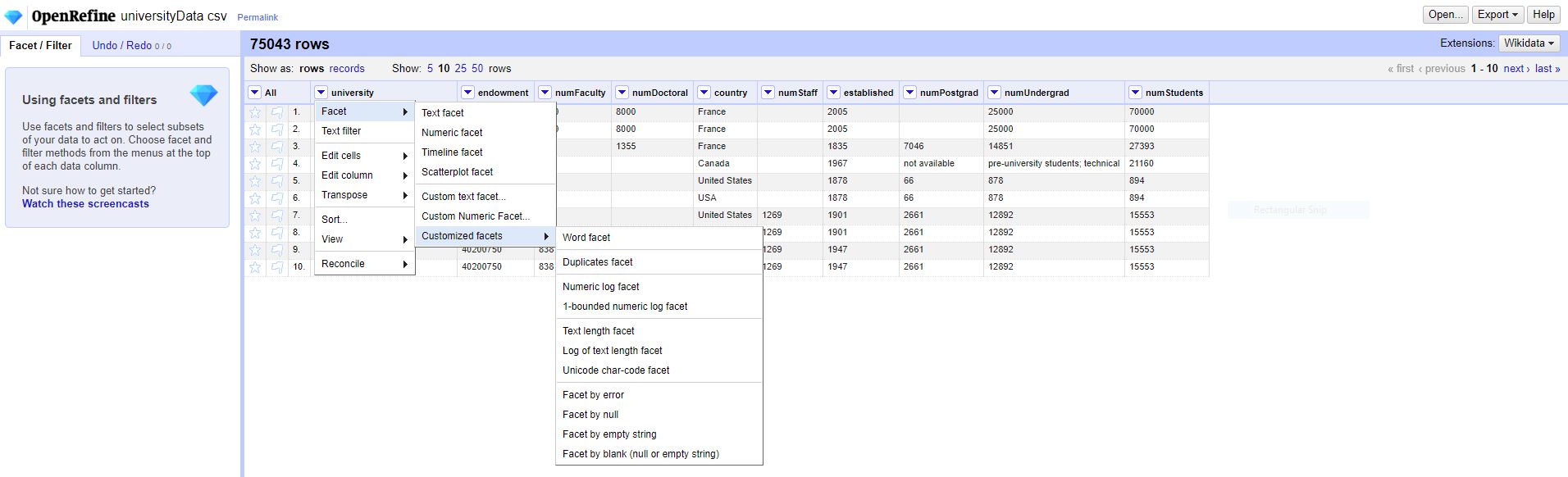
Facets
- Creating and using facets is one of the most powerful features of OpenRefine. Facets can be used to learn more about your data, discover inconsistencies, and select subsets of data for review and cleaning.
- Many types of facets can be created, depending on the data type of the field - text, numeric, timeline, scatterplot. Additionally, there is a list of custom facets built for specific uses, like duplicates, text length, errors, and empty strings. Finally, users can create their own facets using the custom facet builder.
- This workshop will focus mostly on text facets, because our data is not great for demonstrating the others.
Editing Data
- OpenRefine is great for making the same change throughout a column of data. An individual cell can be selected and edited, and all other cells matching that cell can be automatically updated.
- Using facets, the text of the facet can be modified, updating all of the cells with that same data.
Transforming Data
- OpenRefine includes some basic “Common Transforms”, including trimming and collapsing whitespace, change the text case, and converting cells to different datatypes.
- Additionally, you can write your own transforms using the General Refine Expression Language (GREL). GREL is incredibly powerful, and we are going to look at a few examples:
- Clean-up character encoding problems
value.unescape("url")
- Add to a string
value + " random thing"
- Replace string in cells
value.replace("Pittsburgh", "Pgh")value.replace("~", "").replace(",", "").replace("-", "")
- Remove duplicate comma separated entries in a cell
value.split(", ").uniques().join(", ")
- Convert number with text to number
toNumber(value.replace(" million", ""))*1000000
- Clean-up character encoding problems
- This is just the basics. GREL documentation and recipes are available on the OpenRefine wiki.
Clustering
- OpenRefine includes a set of text clustering algorithms. The different algorithms are best suited for different types of applications, but navigating through the different options often helps considerably when attempting to normalize data.
- Learn more about the text clustering algorithms - Clustering In Depth - on the OpenRefine wiki.
Creating New Columns
- It is often helpful to create a new column based on an existing column. You may want to duplicate the information in the column to protect the original data, or perform some transformation on the column or modify the data.
Splitting Columns
- Sometimes columns will contain compound headings, for example keywords, subject terms, or names split by a comma or semi-colon. OpenRefine allows you to split that column into different cells or different columns.
- You might split into different columns if you need to perform different actions on those data types. It can be a little challenging to merge data split into columns back into a single column, because the “+” operator in GREL will break on a blank node. You can do this by using “Facet by blank” and working backwards, combining a cell at a time.
- You might want to split a multi-value cell in multiple cells if you want to perform the same actions over all of them. This can be useful when you are creating text facets to learn more about your headings or look for inconsistencies in your data. Unfortunately, this data does not have great example data, but we will perform this action in the Web Scraping section of the workshop.
Removing Duplicate Rows
- Finding and removing duplicate rows can be done in OpenRefine. There is a built in facet for finding duplicate values in a field that will help you to review and identify duplicate records.
- Once duplicates are identified, the data is typically sorted on the duplicates, then the Blank-down tool is used to remove all but the first instance. This is followed by faceting by blank on the column and removing all rows.
Working with Different Data Types
- When we were on the OpenRefine data preview page, we had the option to attempt to automatically identify data types. OpenRefine will attempt to convert the data to numbers or dates, as appropriate. Typically, I leave this unchecked. When you are working with the data, you can always use the Common Transforms to change the data type of a cell.
- The date format in OpenRefine follows the ISO8601 date format: e.g. 2015-04-11T09:28:00Z. The grel function toDate can convert from dates in string format to date format. A few examples can be found on the GREL Date Functions page of the OpenRefine Wiki.
Interacting with Rows
- OpenRefine primarily deals with columns, but there are some operations that can interact with rows. Typically, this is done from the “All” menu at the front of your data sheet in OpenRefine.
- From the All menu, you can edit columns, allowing you to rearrange and remove data from your project. You can also star or flag rows, as we did in the exercise to remove duplicates above.
Undo / Redo
- OpenRefine has powerful undo and redo capabilities. The Undo/Redo link provides the entire project history, and allows you to step back/forward to any step in the process.
Bringing It All Together
- Maybe we want to start converting the endowment column to numeric values, so others can use them in statistical software or for other purposes.
- We’re going to use a few different processes that we’ve already covered today. There are a bunch of ways that you could do this, and this is one of them.
- Filter by
U(.)?S(.)?- check case sensitive and regex. - Create new column based on this column
- Delete facets to make sure our subset worked. Facet by blank - false
- Text facet - deal with extra text & millions/billions
- Transform
value.replace("US $","")value.replace("US$","").replace("U.S.","").replace("USD","").replace("U.S. $","").replace("$","").replace(",","")
- Common transform - clean leading/trailing space & collapse consecutive whitespace
- Common transform - lower case
- Common transform - convert to numbers
- Numeric Facet, check nonnumeric
- Transform
toNumber(value.replace(" million", ""))*1000000toNumber(value.replace(" billion", ""))*1000000000
- See what is left over, and make decisions about how to update the data, if necessary.
- Filter by
Automating Workflows
- The actions in the Undo/Redo tab can also be saved to create workflows. If you are regularly performing the same actions on a data set, then it might be helpful to save the process and reuse it each time you open the data set.
Exporting a Project or Data Sets
- OpenRefine has a wide variety of outputs and exports. The most straight forward are exporting as TSV, CSV, HTML table, Excel, and ODF spreadsheets.
- Export Project allows you to export your data as an OpenRefine project, with all of your operations in place (including your history of transforms in the Undo/Redo tab). This can be useful if you would like to share your work with a colleague.
- Finally, there are some more advanced options that allow you customize your OpenRefine data output. Since they have fairly specific use-cases, they are not covered in this workshop.
-
- Custom Tabular Exporter allows you to make decisions about which fields will be exported and how they will be represented on export.
- Templating displays your data in JSON, and allows you to convert it to other formats. This can be used to meet specific requirements for your data, including converting the data to XML.
- There are other options, like the SQL Exporter and tools that interact with Wikidata.
-
- Remember! Your exported data is always a copy of what your original data. Your original data is safe!
Fetching Data from a URL
- OpenRefine can connect to the Internet to extract data. As part of the workshop, we will perform a fairly simple geographic coordinate look-up using Open Street Maps Nominatim API - (Nominatim Usage Policy)
- First, create URLs that point at the Nominatim API – add column based on “country” column:
"https://nominatim.openstreetmap.org/search?format=json&email=youremail@email.com&app=google-refine&q=" + escape(value, 'url') - Then, grab JSON from the API using “Add column by fetching URLs” on newly created column
- Finally parse JSON using “Add column based on this column”
with(value.parseJson()[0], pair, pair.lat + ',' + pair.lon)
- First, create URLs that point at the Nominatim API – add column based on “country” column: